To totally unlock this section you need to Log-in
Login
Microsoft SQL Server Management Studio is a commonly-used bit of the Microsoft SQL Server installation, and a decent enough tool for browsing, querying and managing the data.
The "export" of data from a database is quite common for data analysis, and it is even true for SQL Server. Sure, you can link and query the SQL server directly from several tools, but sometimes it is useful to export data in some form to ensure data to remain static, portable, fast, local and not subject to connection issues.
There are 3 methods to do this by using SQL Server Management Studio: they can all produce the same results but some have more options than others. For simple CSV exports these methods work nicely even on big extracts. These methods can serve datafiles with hundreds of millions of rows and a bunch of columns very quickly.
Right clicking the data output grid
You have already ran your query? So the results are in the grid output, the last thing to do is simply right click anywhere on the resulting data and choose Save results as.
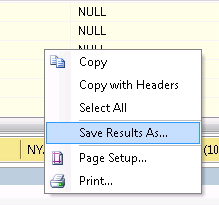
You will be asked where to save what was shown in the grid as a CSV or a tab delimited file.
The downsides of this approach are the following:
- No option here to customise the delimiter or use fixed width text file format. This is fine with nice regular numeric data, but beware of anything with text in that might have the dreaded extra commas or equivalent within the field contents.
- You need to have already got the results of the query output to the grid. This is fine for small result sets but it take be very long time if it’s going to generate millions of rows and you will have to wait.
Output the query to a File instead of the Grid
If you have no need to see the results of the query in the interactive grid, you could output the results of the SQL directly to a file (better approach).
The first thing to do is to go to Query -> Query Options menu. Find the Results -> Text part of the options and check the delimiters (that will be very useful if you will import them in other systems), including column headers, max characters etc.
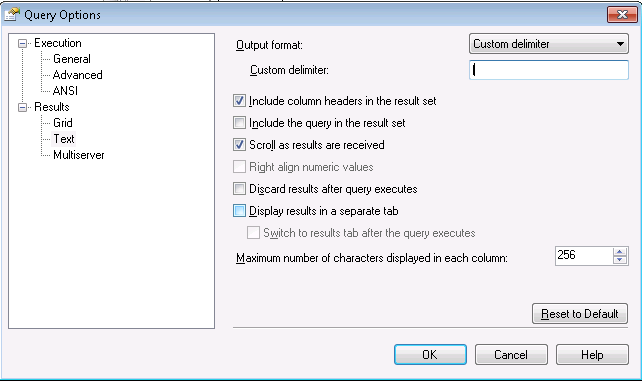
Then, OK on that, and go back to the main SSMS screen, and then press the toolbar button “Results to file” (or Ctrl + Shift + F).
Now when you execute your query it will prompt you for a filename. Enter in the name/location of where you want your text file and it will execute and produce until it’s finished generating it.
Of course you can open a new query tab and carry on working if you want to get stuff done whilst waiting for it to complete.
Warning: SQL server is apt to add an annoying “count of records” line at the bottom of extracts performed in this way. This creates a mostly-blank and invalid record as far as any software importing the output is concerned. To stop this happening, make the first line of your SQL query:
SET NOCOUNT ON
Option 3: Data Export Task
For the maximum levels of configuration, you can use the SQL Import and Export Wizard to get data out into CSV (or a lot of other things).
For this, in the Object Explorer window, right click on the name of the database concerned. It must be the database name; right clicking the table, columns, keys or elsewhere will not give you the correct options.
From this choose Tasks -> Export Data:
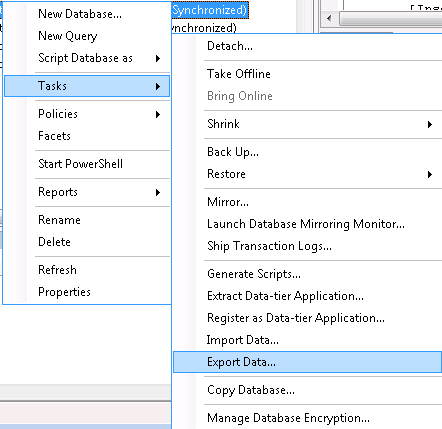
It will then open up an Import/Export wizard: within this wizard you will be able to inserte the name of your SQL server and the database concerned if it isn’t already selected.
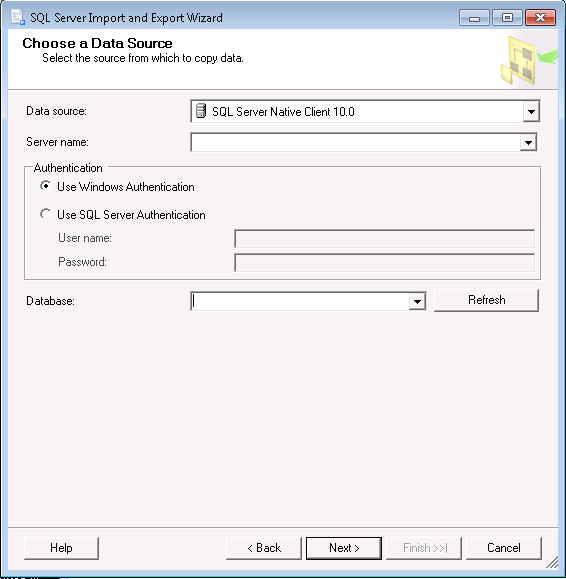
Choose the destination for your data. There are many options here, including copying it to another SQL server database if you have one dedicated to analysis or similar. For a CSV file output select the Flat File Destination option.
Define the filename you want it to output. Then make sure the format, column names options and so on are set as you wish. Don’t worry that you can’t change the delimiter itself on this screen, that comes later.
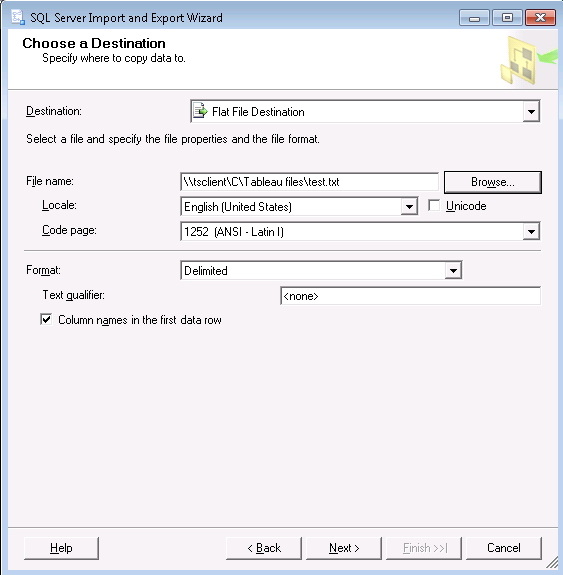
The next screen gives you the chance to copy data from a set of tables of views. But if you have already written some custom SQL (view, T-SQL code, etc.) then pick the Write a query to specify the data to transfer option.
You’ll get blank box which you can type or paste your SQL query in, exactly as you’d run it in the main SSMS environment.
Once that’s done, you will get to a screen where you can pick both a row and column delimiter, assuming you plumped for the delimited output type. Leave source query as Query.
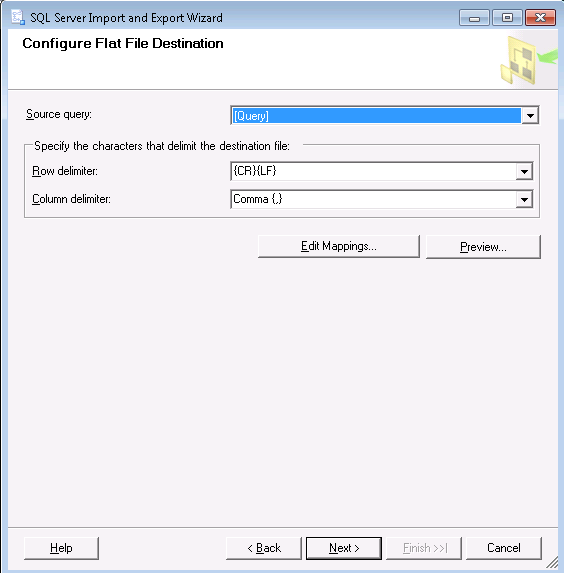
In the following screen you have buttons to quickly preview your data. If you want to perform some basic manipulations, then hit the Edit Mappings button first.
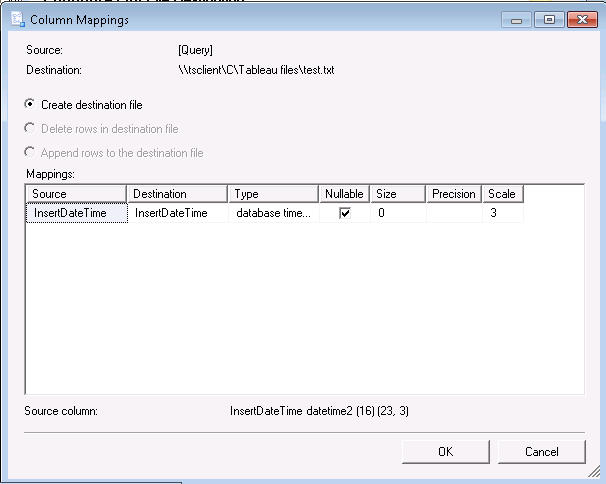
Here you can set options as to whether you want to create a new CSV, or delete/append to an existing one if you happened to pick a filename that already exists.
you can see all the output fields and their characteristics. Click into the grid to change anything that you don’t like – or if it got the data type wrong (which it does sometimes). If you don’t need the column at all in your output, drop down the destination field for that column and chose "".
Once you’re done there, you get to the save/run screen. Here you can either chose to run it immediately, or save the job as an SSIS package if it’s something you need to store and run or re-run in future.
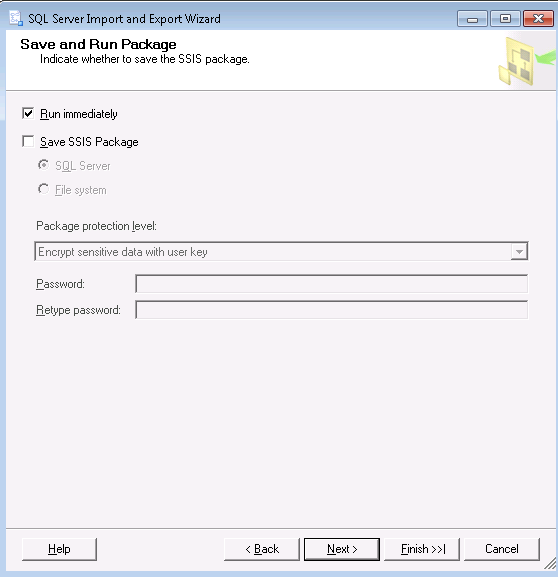
Clicking Next will give you a nice summary of the job you set up. Finally Finish will start the job going, assuming that’s the option you asked for. It will list the stages it needs to go through and you can follow whereabouts it is. Obviously if it is a large and complicated query, this stage may take a long, long time.
The final result of this process will end up with something like the below, and the file you wanted has been created.
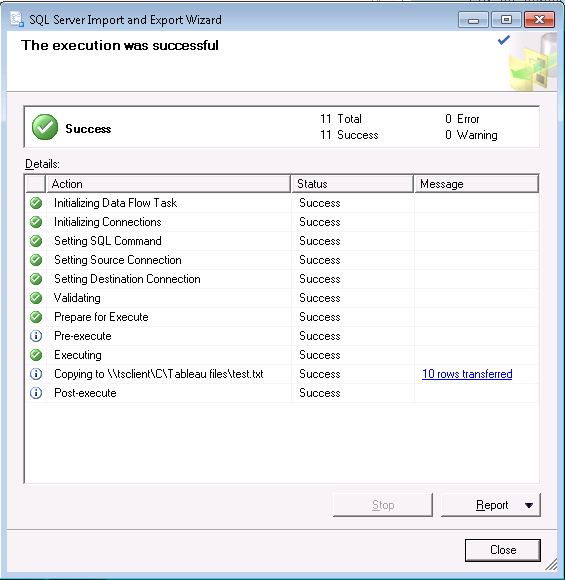
You may get some sort of error message if something went wrong during the process. As a general advice, check always that all fields have been selected with the proper field type (often the incorrect field type is selected automatically) in the above Edit mappings stage. Go back and correct it if so.
Remove field delimiters within field text
The scenario in which people fill text-fields with commas or even pipes and dollars even when you don’t expect ruining the export process with standard delimiters (like commas) is quite common. If you are not bothered about keeping those extra characters within these text fields, then you can just process them out within the query SQL, in which case you’re guaranteed to be safe for CSV export process.
This for example will replace any commas with spaces:
SELECT REPLACE([name_of_your_field],',',' ') AS name_of_your_field FROM ....
Of course this solution is no good if you need to keep the delimiter characters as part of your analysis, but if you can live with removing them it works a treat.
Export SQL Server data to an Excel file using T-SQL code
The Transact-SQL OPENROWSET can be used to export SQL Server data to an Excel file via SSMS.
Before using this method we will have to enable Ad Hoc Distributed Queries option. This can be done by using the sp_configure procedure and executing the following SQL code in a query editor:
EXEC sp_configure 'show advanced options', 1 RECONFIGURE EXEC sp_configure 'Ad Hoc Distributed Queries', 1 RECONFIGURE
After executing the above code, the following message will appear that indicate that the show advanced options and Ad Hoc Distributed Queries options are enabled:
Configuration option ‘show advanced options’ changed from 0 to 1. Run the RECONFIGURE statement to install. Configuration option ‘Ad Hoc Distributed Queries’ changed from 0 to 1. Run the RECONFIGURE statement to install.
If the Ad Hoc Distributed Queries are not enabled you could receive the following error:
Msg 15281, Level 16, State 1, Line 1 SQL Server blocked access to STATEMENT ‘OpenRowset/OpenDatasource’ of component ‘Ad Hoc Distributed Queries’ because this component is turned off as part of the security configuration for this server. A system administrator can enable the use of ‘Ad Hoc Distributed Queries’ by using sp_configure. For more information about enabling ‘Ad Hoc Distributed Queries’, search for ‘Ad Hoc Distributed Queries’ in SQL Server Books Online.
Now, in a query editor type and execute the following code:
INSERT INTO OPENROWSET('Microsoft.ACE.OLEDB.12.0','Excel 12.0;Database=C:\Users\Example\Desktop\SQL Data.xlsx;','SELECT * FROM [Sheet1$]')
SELECT * FROM dbo.DimScenario
But, when executing the above code, the following error may occur:
OLE DB provider “Microsoft.ACE.OLEDB.12.0” for linked server “(null)” returned message “The Microsoft Access database engine cannot open or write to the file ”. It is already opened exclusively by another user, or you need permission to view and write its data.”. Msg 7303, Level 16, State 1, Line 1 Cannot initialize the data source object of OLE DB provider “Microsoft.ACE.OLEDB.12.0” for linked server “(null)
In this case, the error is similar when we are using a linked server (and the OPENROWSET is a sort of linked server) then a temporary DSN (Data Source Name) is created in the TEMP directory for the account that started the SQL Server service. This is typically an account that is an administrator on the machine.
However, the OLEDB provider will execute under the account that called it. This user can even be sysadmin on the SQL Server, but as long as this user is not an administrator on the machine, it will not have Write access to the TEMP directory for the SQL Server service account.
One way for resolving this issue is to open SSMS as an administrator and execute the code again. But this time, another error may appear:
Msg 213, Level 16, State 1, Line 1 Column name or number of supplied values does not match table definition.
To resolved this, open excel file (e.g. SQL Data.xlsx) for which is planned to store the data from SQL Server table (e.g. dbo.DimScenario) and enter the column names which will represent the column names from the DimScenario table:
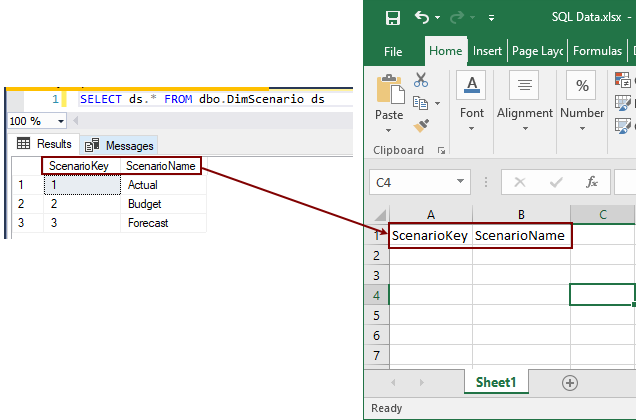
Close the SQL Data.xlsx file and once again execute the code:
Now, the following message will appear:
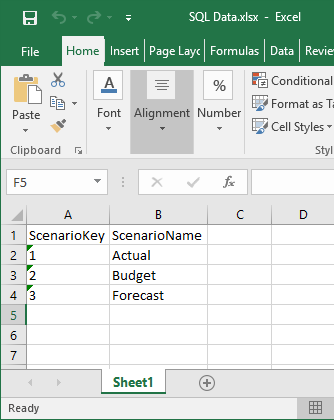
(3 rows affected)
Finally, the data from the SQL Server table are copied into the Excel file:
PowerShell Invoke-Sqlcmd
PowerShell is an extremely popular command line shell to automate tasks. We can export the SQL Server query results to a txt file by executing the following cmdlets:
Invoke-Sqlcmd -InputFile "C:\sql\myquery.sql" | Out-File -filePath "C:\sql\powershelloutput.txt"
In this case Invoke-Sqlcmd will call the script myquery.sql, which contains the T-SQL code that select data from the database, and store the results in a file named powershelloutput.txt. The results will be the following:
If you have to extract data directly to .csv file (in CSV format) we will have to follow this quick procedure.
First we will have (we could do this in other ways too) to save the SQL query we need into a PowerShell variable:
$sql = “SELECT * FROM [AdventureWorks].[Production].[Location]”
Next one-liner will build the PowerShell object and exported to a CSV file (in this case is executed in localhost only. Use -ServerInstance with the -database parameter if is needed to execute query):
Invoke-Sqlcmd -query $sql | Export-Csv -Path c:\temp\excelfile.csv -NoTypeInformation
For more information about the Invoke-SQLcmd use the help in PowerShell:
Help Invoke-SQLcmd -detailed
BCP - Bulk Copy Program
BCP is the Bulk Copy Program that comes with SQL Server. It is used to import data from a data file to SQL Server or from SQL Server to a data file. It is a very fast option. Use it if you have millions of rows and you need to use the command line or if it is easy to call the command line from your program or script.
The following example uses bcp to export the query results to a file named bcp.txt. The -T switch is used to specify that we are using a Trusted Connection (Windows Connection) and -c is used to perform an operation of data type:
bcp "SELECT TOP 5 [BusinessEntityID],[NationalIDNumber],[OrganizationNode],[OrganizationLevel] FROM AdventureWorks2016CTP3.[HumanResources].[Employee] WITH (NOLOCK)" queryout c:\sql\bcp.txt -c -T
To export data in csv format we will need, however, to include the field terminator switch, -t, as in the following example:
bcp myschema.dbo.myTableout myTable.csv -SmyServer01 -c -t, -T
 |